0.XXL-JOB 是什么:
一个分布式任务调度平台(类似定时任务的集群版),用于统一管理、调度和执行各类定时任务。
仓库地址:xuxueli/xxl-job: A distributed task scheduling framework.(分布式任务调度平台XXL-JOB)
特点:
- 可视化管理任务(新增、修改、执行日志一目了然)。
- 分布式部署(调度中心和执行器分离)。
- 支持分片任务、故障转移、失败重试、动态添加/停止任务。
- 支持 Java 原生代码、Shell、Python 脚本等多种执行方式。
XXL-JOB 的分布式调度机制
XXL-JOB 本质上是一个 中心式分布式任务调度平台,由两个部分组成:
- 调度中心(Admin)
- 负责统一管理任务、执行器、调度日志、任务状态等
- 由管理员在 Web UI 上配置任务信息
- 定时扫描数据库任务配置,根据 Cron 表达式或固定时间触发
- 把执行请求通过 HTTP 推送到执行器
- 执行器(Executor)
- 嵌入到你的业务 Spring Boot 服务里
- 负责实际执行任务逻辑
- 启动时向调度中心注册(包含自身地址、心跳、任务 handler 列表)
- 支持分片广播(同一任务可分片并行到多台机器)
- 架构:
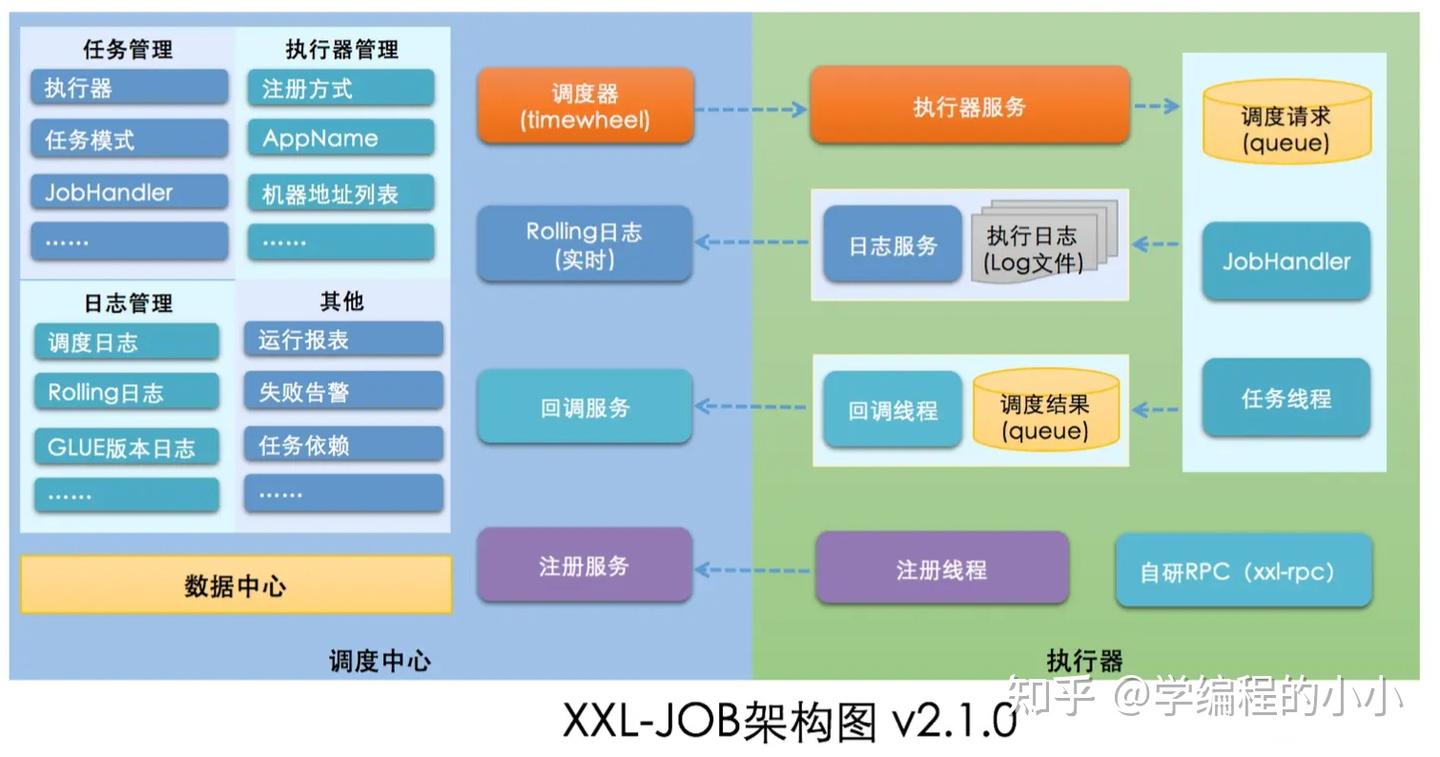
🔹 调度流程简述:
- 调度中心定时根据任务配置触发任务
- 按照路由策略(随机/轮询/一致性Hash/分片广播等)选择执行器
- 调度中心通过 HTTP 调用执行器暴露的
/run接口 - 执行器执行实际业务逻辑,回调结果到调度中心
🔹 分布式能力:
调度日志与运行日志集中在 Admin 中管理
调度中心本身可多节点部署(MySQL存储任务配置,中心之间自动选主)
多个执行器实例同时注册同一任务 → XXL-JOB 支持多种负载策略(分片、广播、故障转移)
1.调度中心(XXL-JOB-ADMIN)部署
下载源代码后有三个包:admin、core、excutor。其中admin是调度中心、core是调度中心和执行器的核心依赖、基础实现。
1.1 执行SQL脚本:
执行 SQL 脚本是为了给 XXL-Job 调度中心搭建必要的 “数据存储基础设施”,没有这些表,调度中心无法正常存储和管理任务、执行器、日志等核心数据,也就无法实现分布式任务调度的功能。这一步是调度中心启动和运行的前提,必不可少。
在doc/db/tables_xxl_job.sql中。
1.2 配置调度中心:
主要配置项说明:
# 服务器端口(默认8080,避免冲突可修改)
server.port=8050
# 日志路径
logging.config=classpath:logback.xml
# 数据库连接配置(需与步骤二的数据库对应)
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 调度中心通讯TOKEN(非空时启用,执行器需匹配该TOKEN才能通信)
xxl.job.accessToken=default_token
# 调度中心国际化配置(默认中文)
xxl.job.i18n=zh_CN
# 调度线程池配置
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
# 调度中心日志表数据保存天数(过期自动清理)
xxl.job.logretentiondays=301.3 登入任务调度中心:
URL:http://localhost:8090/xxl-job-admin
XXL-Job 控制台的默认用户名和密码为 admin/123456。
2.执行器部署示例:
新开个xxljob-demo项目。
2.1添加Maven依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>2.2 执行器配置:
# 应用服务 WEB 访问端口,与下面的通信端口作用不一样
server.port=8091
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8090/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=default_token
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=127.0.0.1
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=302.3 执行器配置类:
@Configuration
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}2.4 添加任务处理器类:
添加任务处理类,交给Spring容器管理,在处理方法上贴上@XxlJob注解。
@XxlJob 是 XXL-JOB 提供的一个 方法级注解,用来声明一个“任务处理器(JobHandler)”。
有了这个注解,XXL-JOB 执行器在启动时就会把你写的方法注册到 XXL-JOB 的 JobHandler 容器中,调度中心在触发任务时就能按名字调用它。
类似于 Spring 的
@RequestMapping,但这是注册给 XXL-JOB 的调度中心用的。
@Component
public class SimpleXxlJob {
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
System.out.println("执行定时任务,执行时间:"+new Date());
}
}3 任务管理
上一步只是写好了任务类、注册好了执行器。要真正执行任务,需要在调度中心的“任务管理”处配置。
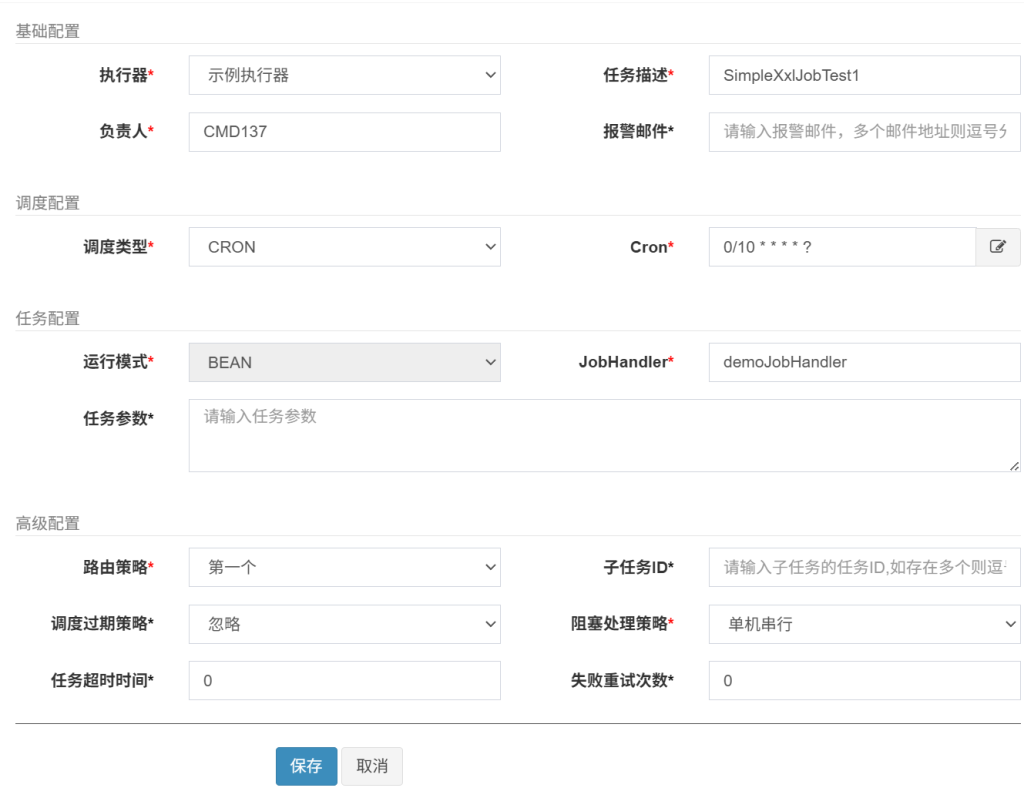
🔹基础配置
1. **执行器 ***
- 是什么:执行器是调度中心的“客户端”,一组机器+进程的集合,负责真正执行任务。
- 怎么选:在调度中心里预先配置“执行器组”,每个执行器对应一个
AppName和一组地址。 - 要点:相同业务或相同服务模块的任务建议共用一个执行器,便于水平扩展和管理。
2. **任务描述 ***
- 是什么:任务的中文/业务描述。
- 怎么填:简洁准确,如“订单超时自动取消”“每天凌晨清理过期日志”。
- 好处:方便在任务列表、报警邮件中快速定位。
3. **负责人 ***
- 是什么:任务出问题时通知的责任人。
- 怎么填:真实负责该任务的开发或运维人员。
- 好处:报警邮件、调度中心界面都能显示负责人。
4. **报警邮件 ***
- 是什么:任务执行失败时调度中心发送告警的邮箱地址(可多邮箱逗号分隔)。
- 怎么用:生产环境建议填公司邮件组,多个任务共用一个组也行。
- 注意:只在任务失败或超时触发报警。
🔹调度配置
5. **调度类型 ***
- 固定CRON:按 Cron 表达式定时调度。
- 固定间隔(FIX_RATE/FIX_DELAY):按固定秒数间隔执行。
- 无:不自动调度,只能手动触发或被子任务触发。
大部分企业定时任务都用 Cron。
6. **Cron ***
- 是什么:调度时间表达式。
- 举例:
0 0/5 * * * ?:每 5 分钟执行一次0 0 2 * * ?:每天凌晨 2 点
- 注意:要验证 Cron 是否正确,可以在调度中心自带的 Cron 工具测试。
🔹任务配置
7. **运行模式 ***:BEAN
- 是什么:任务的执行方式。常见有:
- BEAN(Java Bean):执行器 Spring 容器中
@XxlJob标注的方法(最常用)。 - GLUE(Java)、GLUE(Shell)、GLUE(Python):在调度中心直接写脚本。
- BEAN(Java Bean):执行器 Spring 容器中
- 为什么常用 BEAN:可版本管理、IDE 开发调试,生产更稳定。
8. **JobHandler ***
- 是什么:执行器里真正执行的方法名。
- 怎么对应:执行器代码里:
@XxlJob("orderTimeoutHandler") public void orderTimeoutJob() { // your logic }在调度中心 JobHandler 就填orderTimeoutHandler。
9. **任务参数 ***
- 是什么:调度中心传递给执行器的运行参数(字符串)。
- 用途:可以传 JSON、时间区间、批次号等。
- 在代码里获取:
String param = XxlJobHelper.getJobParam();
🔹高级配置
10. **路由策略 ***
- 是什么:当执行器有多台机器时,调度中心把任务分配到哪台机器。
- 常见策略:
- FIRST(固定第一台)
- ROUND(轮询)
- RANDOM(随机)
- SHARDING_BROADCAST(分片广播:每台都执行一部分)
- 选哪个:批处理、幂等任务可 SHARDING_BROADCAST;普通定时任务可 ROUND。
11. **子任务 ID ***
- 是什么:当前任务执行成功后自动触发的其他任务(可多个,逗号分隔)。
- 用途:实现“任务链”,如 A 任务成功后触发 B、C。
12. **调度过期策略 ***(默认:忽略)
- 是什么:调度中心宕机或延迟时,原定时间的任务是否补执行:
- 忽略:不执行过期任务。
- 立即补偿执行:恢复后立刻补跑。
- 建议:对关键数据处理任务可以选“补偿执行”。
13. **阻塞处理策略 ***(默认:单机串行)
- 是什么:同一个任务上一次还没跑完,新调度又来了怎么办:
- 单机串行:排队等前一个执行完。
- 丢弃后续调度:只跑第一个,丢弃后续。
- 覆盖前一次调度:停止前一次,直接执行最新一次。
- 选哪个:耗时长的任务建议“串行”;幂等短任务可“覆盖”。
14. **任务超时时间 ***(默认 0)
- 是什么:单次任务执行的最大时间(秒),0 表示不限制。
- 作用:超过时间强制终止并记录失败。
- 建议:关键任务设合理超时,避免“卡死”。
15. **失败重试次数 ***(默认 0)
- 是什么:任务执行失败后自动在执行器重试的次数。
- 要点:重试在同一执行器节点,且立刻执行。
- 建议:幂等任务可以大于 0;非幂等任务慎用重试或在代码里做好幂等保障。
设置完这些即可在外部的操作启动任务/执行一次等操作。
3.GLUE模式:
3.1什么是 GLUE(Java)
GLUE 的英文意思是“胶水”,在 XXL-JOB 里指一种“在线脚本”功能。
当我们在任务管理页面里将“运行模式”选为 GLUE(Java) 时,意味着:
任务执行代码不再来源于执行器的 Spring Bean,而是直接在调度中心网页上编写 Java 脚本,由执行器动态加载并执行。
换句话说:调度中心 = 代码仓库 + 编辑器,执行器 = 动态运行容器。
下面给出示例:
GLUE IDE:
在线编辑代码:
package com.xxl.job.service.handler;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.IJobHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.example.xxljobdemo.service.SimpleService;
public class DemoGlueJobHandler extends IJobHandler {
@Autowired
private SimpleService simpleService;
@Override
public void execute() throws Exception {
String tempResult = simpleService.getTime();
XxlJobHelper.log(tempResult);
}
}
Service代码:
@Service
public class SimpleService {
public String getTime() {
LocalDate now = LocalDate.now();
String result = "执行任务:"+now.toString()+"for GLUE";
System.out.println(result);
return result;
}
}另外,XxlJobHelper.log()会记录在调度中心的调度日志的执行日志中。
4.多集群-负载均衡-路由算法:
调度路由算法讲解
当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):固定选择第一个机器LAST(最后一个):固定选择最后一个机器;ROUND(轮询):依次的选择在线的机器发起调度RANDOM(随机):随机选择在线的机器;CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
5.XXL-JOB 分片广播(Sharding Broadcast)
5.1.分片广播是什么:
当一个 XXL-JOB 任务配置成 “分片广播”路由策略时,调度中心不会只挑一台执行器机器去跑任务,而是会对当前执行器集群里的每台机器都下发一次任务,并在请求里附带分片信息。
这样每台机器(或每个分片线程)可以只处理自己负责的那部分数据,实现水平扩展。
5.2.调度中心怎么做
- 先查这个执行器下有几台实例(N 台)。
- 再按照你设置的“分片总数”(ShardTotal),调度中心给每台机器发请求,每次请求都包含两个关键参数:
- shardIndex(分片序号,0 开始)
- shardTotal(分片总数)
默认情况下:
- 如果机器数 = 分片总数,每台机器执行一个分片。
- 如果分片总数 > 机器数,调度中心会在每台机器上轮流多发几个分片,直到分片总数分配完。
5.3.代码里怎么拿分片信息
XXL-JOB 提供了辅助类 XxlJobHelper 来读取分片参数:
int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片序号
int shardTotal = XxlJobHelper.getShardTotal(); // 分片总数可用模运算简单实现分片: i % shardTotal == shardIndex。
5.4.定时给用户分片发券案例
5.4.1 DAO层:
/**
* 模拟用户数据的DAO层,用static Map代替数据库。
* 在真实项目里这里会写MyBatis/JPA去查数据库。
*/
public class UserDao {
// 用static的Map模拟数据库用户表:key=用户ID,value=用户名
private static final Map<Long, String> USER_TABLE = new HashMap<>();
static {
// 模拟一些用户数据
USER_TABLE.put(1L, "Alice");
USER_TABLE.put(2L, "Bob");
USER_TABLE.put(3L, "Charlie");
USER_TABLE.put(4L, "David");
USER_TABLE.put(5L, "Emma");
USER_TABLE.put(6L, "Frank");
USER_TABLE.put(7L, "Grace");
USER_TABLE.put(8L, "Henry");
USER_TABLE.put(9L, "Ivy");
}
/**
* 查询所有符合发券条件的用户ID。
* 在真实项目里可以有复杂的条件。
*/
public List<Long> findEligibleUserIds() {
// 简单起见,这里就直接返回全部用户ID
return USER_TABLE.keySet().stream().sorted().collect(Collectors.toList());
}
/**
* 模拟发券动作
*/
public void sendCoupon(Long userId) {
String userName = USER_TABLE.get(userId);
System.out.println("向用户【" + userName + "】(ID:" + userId + ") 发放优惠券");
}
}5.4.2 分片业务:
/**
* 定时给用户发券的JobHandler。
*
* 配置要点:
* - 在调度中心新建任务,执行器选择部署本Job的服务。
* - 路由策略选择“分片广播(Sharding Broadcast)”。
* - 高级配置里填写分片总数(如6)。
*/
@Component
public class SendCouponJobHandler {
private final UserDao userDao = new UserDao();
/**
* XXL-JOB 调度入口。
* 每台执行器实例收到请求时都会执行此方法,
* 并且调度中心会在请求中带上当前分片序号和总分片数。
*/
@XxlJob("sendCouponJob")
public void sendCouponJob() throws Exception {
// 1. 读取当前分片序号和分片总数
int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片号(0开始)
int shardTotal = XxlJobHelper.getShardTotal(); // 总分片数(调度中心配置)
XxlJobHelper.log("开始执行分片 [" + shardIndex + "/" + shardTotal + "]");
System.out.println("开始执行分片 [" + shardIndex + "/" + shardTotal + "]");
// 2. 查询符合条件的用户
List<Long> allUserIds = userDao.findEligibleUserIds();
// 3. 按分片规则拆分数据
// - shardTotal = 总分片数
// - shardIndex = 当前分片号
// 这里用模运算简单实现: i % shardTotal == shardIndex
for (int i = 0; i < allUserIds.size(); i++) {
if (i % shardTotal == shardIndex) {
Long userId = allUserIds.get(i);
try {
// 4. 发券动作(调用DAO模拟)
userDao.sendCoupon(userId);
XxlJobHelper.log("分片[" + shardIndex + "] 成功给用户 " + userId + " 发券");
System.out.println("分片[" + shardIndex + "] 成功给用户 " + userId + " 发券"+ LocalDateTime.now());
} catch (Exception e) {
// 5. 记录错误
XxlJobHelper.log("分片[" + shardIndex + "] 用户 " + userId + " 发券失败:" + e.getMessage());
}
}
}
XxlJobHelper.log("分片 [" + shardIndex + "/" + shardTotal + "] 执行完成");
}
}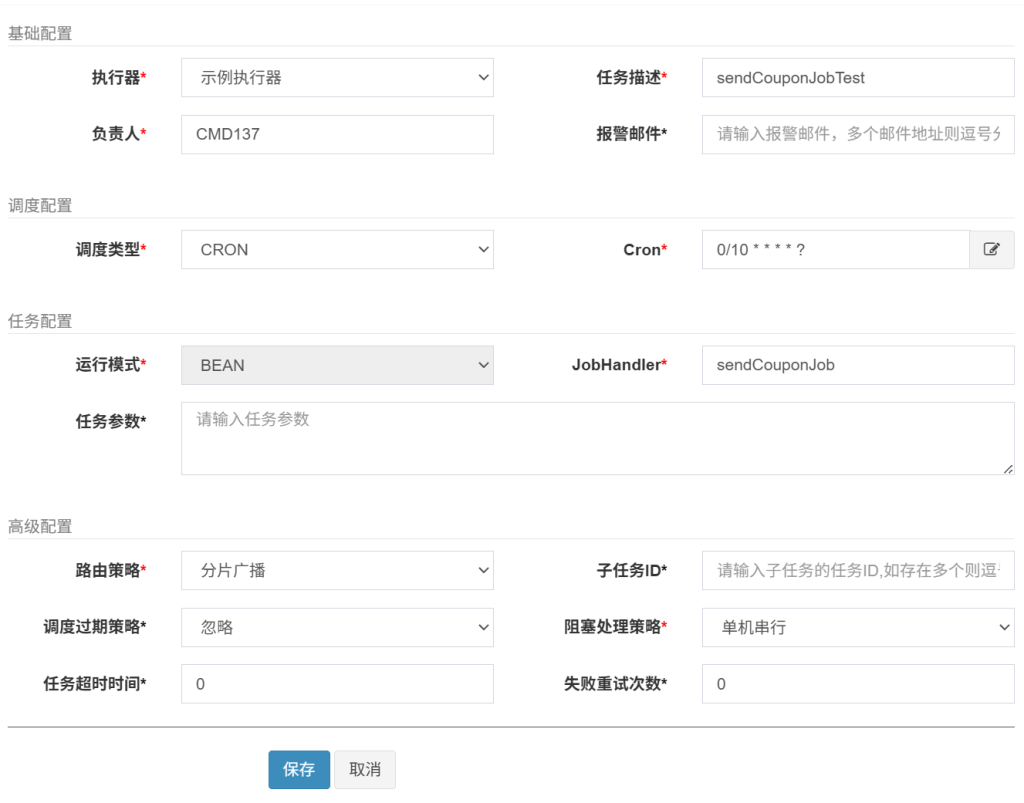
得到结果:
开始执行分片 [0/2]
向用户【Alice】(ID:1) 发放优惠券
分片[0] 成功给用户 1 发券2025-09-11T14:02:30.055970200
向用户【Charlie】(ID:3) 发放优惠券
分片[0] 成功给用户 3 发券2025-09-11T14:02:30.055970200
向用户【Emma】(ID:5) 发放优惠券
分片[0] 成功给用户 5 发券2025-09-11T14:02:30.059968500
向用户【Grace】(ID:7) 发放优惠券
分片[0] 成功给用户 7 发券2025-09-11T14:02:30.060970200
向用户【Ivy】(ID:9) 发放优惠券
分片[0] 成功给用户 9 发券2025-09-11T14:02:30.060970200开始执行分片 [1/2]
向用户【Bob】(ID:2) 发放优惠券
分片[1] 成功给用户 2 发券2025-09-11T14:02:50.042518900
向用户【David】(ID:4) 发放优惠券
分片[1] 成功给用户 4 发券2025-09-11T14:02:50.042518900
向用户【Frank】(ID:6) 发放优惠券
分片[1] 成功给用户 6 发券2025-09-11T14:02:50.042518900
向用户【Henry】(ID:8) 发放优惠券
分片[1] 成功给用户 8 发券2025-09-11T14:02:50.042518900